Introduction
HTTP request smuggling is a web application vulnerability that leverages discrepancies and ambiguity in how frontend and backend servers interpret request boundaries. With numerous possible attack vectors leading to requests that are parsed differently at each stage, an attacker can bypass security controls, hijack user sessions, access sensitive data, and poison shared caches, among other serious impacts.
This white paper aims to provide an overview into request smuggling attacks including the origins, trends, and technical standards, supported by real-world CVE examples. It also explores the broader impact of this vulnerability and discusses whether mitigation strategies are enough to help secure web infrastructure from this seemingly persistent threat.
HTTP Standards & RFC
Before we can understand how request smuggling works, we need to understand why it works – starting with the HTTP protocol and its specifications.
Requests for Comments (RFC) are the authoritative technical specifications published by the Internet Engineering Task Force (IETF) that define how internet protocols work. They are not just guidelines, but instead are the official source for how protocols like HTTP should be implemented, interpreted, and interoperate between systems. When followed precisely, RFCs help ensure consistent behaviour across servers, clients, proxies, and intermediaries.
RFC 2616, published in June 1999, laid out the foundational rules for structuring and parsing HTTP/1.1 messages. In 2014, it was superseded by RFC 7230–7235 to address vagueness and tighten specifications, including some explicitly aimed at reducing request smuggling risks. Most recently, in June 2022, the standards were updated again: RFC 9110 now defines the semantics of HTTP, while RFC 9112 specifies the message framing and core protocol mechanics for HTTP/1.1.
An example of language around preventing request smuggling can be found in RFC 9112, Section 6.3.3 on Message Body Length. It states:
If a message is received with both a Transfer-Encoding and a Content-Length header field, the Transfer-Encoding overrides the Content-Length.
This rule exists because having two competing indicators for where the message body ends would otherwise create ambiguity in parsing. In practice though, not all intermediaries and servers apply this rule consistently, some might trust the Content-Length and others the Transfer-Encoding. This divergence in implementation is exactly the kind of parsing discrepancy that attackers exploit in HTTP request smuggling.
Having a foundation that is actively maintained by the IETF and adhered to by developers is crucial in helping prevent ambiguities and inconsistencies in protocol specifications and their implementations. It serves as a real-world reminder that the seemingly abstract language of RFCs is not just technical documentation, but the very foundation upon which the security and reliability of the web are built. Therefore, it is important to acknowledge that some request smuggling vulnerabilities are a direct consequence of inconsistent adherence to these standards
However, the persistent presence of request smuggling attacks highlights a critical reality, achieving uniform adherence to RFC specifications across all HTTP parsers is an impractical expectation. Subtle variations in interpretation, implementation, and tolerance for non-standard behaviour inevitably emerge, creating conditions in which this vulnerability persists.
In other words, while proper implementation and strict adherence to RFCs help prevent many flaws, HTTP/1.1 is a complex protocol that is inherently susceptible to smuggling attacks.
Attack Vectors
This paper focuses on three primary areas where ambiguities in HTTP parsing intersect directly with RFC specifications:
- Conflicting Content-Length and Transfer-Encoding headers
- Carriage return/line feed (CRLF) handling
- Duplicate header management
These vectors are discussed in detail due to their close relationship with the HTTP standards. However, they are not the only techniques used in request smuggling. Malformed header casing and whitespace, transfer-encoding chunk size obfuscation, and HTTP/2 downgrade attacks remain prevalent in real world exploitation but are outside the scope of this paper for the sake of brevity.
Content-Length / Transfer-Encoding
Handling of Content-Length and Transfer-Encoding headers is the most widely recognised avenue for HTTP request smuggling. First publicly documented by Watchfire in 2005, it remains a foundational example of parsing inconsistencies.
According to RFC 9112 §6.3.3 (Message Body Length), if both headers are present, Transfer-Encoding must take precedence, and intermediaries must remove the Content-Length header before forwarding. The message body length is determined only after all Transfer-Encoding rules have been applied.
If an intermediary or endpoint fails to follow these rules, for example, by honouring Content-Length instead, forwarding both headers unchanged, or inconsistently applying parsing logic, downstream components may interpret the end of the request body differently, creating opportunities for request smuggling.
CRLF Handling / Line Terminator Mismatch
Improper handling of carriage return and line feed characters (CRLF) is another source of parsing discrepancies that can enable request smuggling. According to RFC 9112 §2.2 (Message Parsing), senders must not generate a bare carriage return (CR) outside of message content, and recipients encountering such a sequence must treat the message element as invalid or replace the CR with a space before processing or forwarding.
In addition, if a recipient detects whitespace between the start-line and the first header field, it must either reject the message outright or discard all whitespace preceded lines until a correctly formed header is encountered or the header section terminates. Failure to enforce this behaviour can allow attackers to smuggle hidden headers or payloads past certain parsers due to discrepancies in enforcing the RFC rules, leading to request smuggling vulnerabilities.
Duplicate Headers
Ambiguities in the handling of duplicate HTTP headers present another vector for request smuggling. While RFC 7230 (§3.3.2 and §3.3.3) provided explicit guidance on the treatment of multiple Content-Length or Transfer-Encoding headers, RFC 9112, despite obsoleting RFC 7230, does not directly address duplicate message framing headers, instead deferring to the general field combination rules in RFC 9110.
According to RFC 9110 §5.2 (Field Lines and Combined Field Value), a field section may contain multiple instances of the same field name, with the effective value determined by concatenating their individual values in order, separated by commas. This approach is safe for many header types (e.g. Accept or Cache-Control), but when applied to framing-related headers such as Content-Length or Transfer-Encoding, it can create ambiguity in determining message boundaries.
If intermediaries or endpoints inconsistently apply these rules, such as by concatenating duplicate Content-Length values, honouring only the first or last occurrence, or ignoring duplicates entirely, parsers can desynchronise – leading to request smuggling.
The History of Request Smuggling
HTTP request smuggling has a history spanning over two decades. From its first public disclosure in 2005 to modern research, request smuggling has seen an evolution in variants, detection, and mitigation, yet the threat is more prevalent than ever before.
Before exploring the trends and real-world examples of request smuggling, it is worth understanding that the attack’s history is an amalgamation of protocol specifications and professional research that has led us to where we are today. Each stage in this history reflects a push-and-pull between standardisation efforts, through RFC updates, and the ways different servers and intermediaries handle HTTP messages in practice.
June 1999 – RFC 2616 Section 4.4: Message Length
The foundational HTTP/1.1 specification introduced rules for message length and framing. These guidelines laid the groundwork that later, when not properly implemented or misinterpreted, led to request smuggling.
2005 – WatchFire HTTP Request Smuggling Report
WatchFire researchers published the first detailed public analysis of HTTP Request Smuggling, demonstrating how inconsistent parsing between frontend and backend servers could be abused to bypass security controls.
June 2014 – RFC 72300 9.5. Request Smuggling
The updated HTTP/1.1 specification explicitly recognises the risk of request smuggling and begins to provide guidance to reduce ambiguity.
November 2018 – HTTP Request Smuggler Extension
The BurpSuite extension by James Kettle is released to facilitate testing and exploitation of HTTP Request Smuggling vulnerabilities. This will eventually become the most widely used tool of this class.
August 2019 – HTTP Desync Attacks: Request Smuggling Reborn
Portswigger’s Director of Research, James Kettle, publishes a paper on exploiting HTTP desynchronisation which revived and modernised it. This led to widespread discovery in bug bounties and had a noticeable impact on CVE discoveries.
August 2020 – HTTP Request Smuggling in 2020 – New Variants, New Defenses and New Challenges
Amit Klein at SafeBreach labs reveals new attack techniques and research into effective mitigation techniques.
September 2020 – h2c Smuggling: Request Smuggling Via HTTP/2 Cleartext
Jake Miller at BishopFox publicly discloses a new technique “h2c smuggling”.
August 2021 – HTTP/2: The Sequel is Always Worse
James Kettle from Portswigger further explores request smuggling vulnerabilities specific to HTTP/2.
August 2025 – HTTP/1.1 must die: the desync endgame
Once again James Kettle reveals new HTTP desynchronisation attacks. He argues that HTTP/1.1 is inherently insecure and is unfixable through patching.
CVE Trends
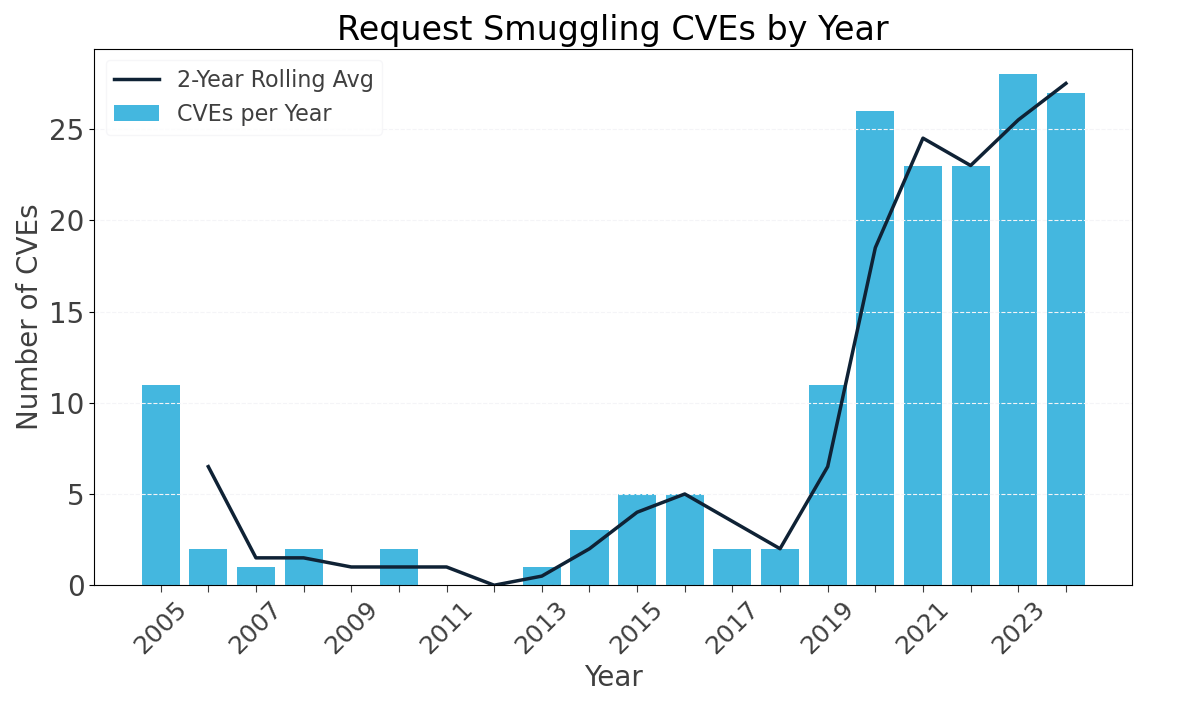
The historical trend of publicly disclosed HTTP request smuggling vulnerabilities reveals two distinct periods of increased activity. The first surge occurred following the original research published by WatchFire in 2005, which was the first organisation to publicly analyse and document request smuggling attacks. This early work sparked initial interest and led to an expected jump in CVEs, with 11 reported that year. However, after this initial spike, disclosures tapered off significantly and remained relatively low for over a decade, with annual counts mostly below five.
The second distinct surge followed the publication of James Kettle’s initial research on HTTP desynchronisation attacks in August 2019. His work reinvigorated interest and awareness around request smuggling by unveiling new techniques and demonstrating their widespread real-world impact. The effect is evident in the data; out of all recorded request smuggling CVEs, approximately 79% have been disclosed from 2019 onward.
This surge reflects the improved detection capabilities facilitated by Kettle’s research and accompanying tools, such as the BurpSuite HTTP Request Smuggling extension. It also speaks to the broad reach of his work that significantly raised awareness, leading to increased attention from security researchers.
The full impact of the latest PortSwigger research, “HTTP/1.1 Must Die: The Desync Endgame,” and version 3.0 of the HTTP Request Smuggling extension remains to be seen. However, it is likely to drive a further increase in the already high volume of request smuggling vulnerabilities.
CVE Examples
Although the number of request smuggling CVEs reported each year has never exceeded 28, the potential impact of each vulnerability is often far greater than the raw numbers suggest. A single vulnerability in widely deployed software, such as Apache, can expose hundreds of thousands, if not millions of websites to exploitation. This amplifies the risk and highlights why even a relatively small number of CVEs can represent a substantial security threat across the internet.
The following CVEs showcase how deviations from RFC standards in widely used web components have resulted in exploitable request smuggling vulnerabilities.
CVE‑2021‑33037 – Apache Tomcat
In certain configurations, Apache Tomcat failed to correctly parse the Transfer-Encoding header, creating conditions for HTTP request smuggling when deployed behind a reverse proxy. The vulnerability stemmed from three specific parsing and validation errors:
- If the client declared it would only accept an HTTP/1.0 response (via the Connection or Upgrade headers), Tomcat would ignore the Transfer-Encoding header entirely. This behaviour created inconsistencies between how Tomcat and an upstream proxy might interpret the request body length.
- Although RFC 7230 (and subsequently RFC 9112) deprecated the transfer encoding value called “identity”, which indicated no transfer encoding, Tomcat continued to honour it. A malicious client could leverage this to modify body parsing logic in ways an upstream component might not replicate, creating mismatch.
- RFC-compliant parsers require that if chunked transfer coding is present, it must be the final encoding applied in the Transfer-Encoding header. This was not the case for Apache Tomcat as it did not enforce this.
CVE‑2022‑32214 – Node.js (llhttp parser)
In affected versions of the llhttp parser used internally by Node.js’ http module, it did not strictly enforce the use of the carriage return + line feed (\r\n, CRLF) sequence to delimit HTTP requests. Instead, partial line termination sequences were erroneously accepted leading to request smuggling when behind a reverse proxy or load balancer.
This parsing weakness violated RFC 9112 §2.2 – Message Parsing, which explicitly requires that if a single carriage return character is received without a following line feed, it must either be rejected or replaced with a space (SP) character before processing. The intention behind this rule is to ensure consistent request parsing and to prevent header boundary confusion between different components.
CVE‑2023‑47641 – aiohttp (Python async HTTP framework)
Aiohttp is an asynchronous HTTP client/server framework which, in affected versions, was vulnerable to an inconsistent HTTP message interpretation issue when both Content-Length (CL) and Transfer-Encoding (TE) headers were present in a request.
As previously mentioned, RFC 9112 §6.3.3 (Message Body Length) requires that if both CL and TE are present, the TE directive must take precedence. In practice aiohttp would parse a TE value containing the string “chunked” as chunked encoding while most reverse proxies would ignore a non-standard header and instead revert to CL to determine the body length. This mismatch caused a desynchronisation between the two and therefore allowed for request smuggling.
Impact
The impact of request smuggling can vary widely, depending on the application and implementation. Understanding the breadth and depth of these potential outcomes is essential for accurately assessing the risk such vulnerabilities pose in modern, distributed web architectures. This section highlights some of the most common impacts from request smuggling.
Bypassing Security Controls
Request smuggling can allow malicious requests to bypass protective layers such as Web Application Firewalls (WAFs), rate limiting and other restrictions residing on frontend and even backend servers.
If a server rejects or sanitises a request, but the smuggled portion is passed unchanged, security policies can be effectively bypassed. This makes it possible to reach endpoints or perform actions that should otherwise be blocked.
While frontend servers such as reverse proxies are most likely to be impacted by this, backend control bypasses are theoretically possible, especially if checks depend on correctly framed request boundaries. An example of this is CVE-2024-1135 where Gunicorn, a web server gateway interface (WSGI), failed to properly validate conflicting Transfer-Encoding headers which allowed for the bypassing of security and endpoint restrictions on the application.
Hijacking User Sessions
By crafting smuggled requests that are processed in the context of another user’s session, attackers can intercept session cookies, tokens, and other sensitive identifiers. This enables full account takeover without the need for credential guessing or phishing, and in many cases the activity blends seamlessly into legitimate traffic patterns.
This was demonstrated in Jame Kettle’s 2019 PortSwigger research where he demonstrated stealing authentication cookies in the workflow management tool Trello.
Server-Side Request Forgery (SSRF)
Smuggled requests can enable Server-Side Request Forgery (SSRF), tricking the backend server into making unauthorised requests to arbitrary internal or external hosts. This often ties directly to the bypassing of security controls, such as filters designed to block SSRF attempts, allowing malicious requests to evade detection and execute successfully. Consequently this often leads to further compromise of infrastructure.
Cache Poisoning
Many high-traffic applications rely on shared caches or CDNs to improve performance. Request smuggling can allow an attacker to insert malicious responses into these caches, causing future visitors to receive attacker-controlled content. The scope of impact is magnified when caches are distributed globally, potentially affecting millions of users almost instantly. This type of attack is detailed in the latest Portswigger research.
Cross-Site Scripting (XSS)
While request smuggling is not a XSS attack vector, it can be used to “upgrade” a XSS attack by acting as a delivery mechanism to users at scale. By smuggling malicious payloads and having them returned to another user via desynchronisation, attackers can easily cause victims’ browsers to execute arbitrary JavaScript. This can also be combined with session hijacking to escalate the attack’s effectiveness.
Mitigations
While HTTP/2 is a more complex binary protocol compared to the text-based HTTP/1, it significantly reduces the risk of request smuggling by removing ambiguity around message length. Although HTTP/2 is not yet universally adopted across all web technologies, support continues to grow. The protocol has faced its own issues, such as rapid reset and CONTINUATION frame floods, but to date, no fundamental flaws have emerged that enable consistent exploitation.
Preventing request smuggling vulnerabilities in HTTP/1.1 requires a proactive approach in both tech stack decision making and ongoing application maintenance. The following mitigations should be considered.
- Migrate to HTTP/2 Technologies – use intermediaries and backends that support the protocol and ensure they are not downgrading it.
- Avoid niche web servers and instead opt for common ones such as Apache and NGINX.
- Regularly scan and test applications using tooling such as the BurpSuite Request Smuggler Extension.
- Where intermediaries offer additional normalisation and validation capabilities, ensure they are enabled.
- Implement a consistent patch management process for all server and application components.
Conclusion
It has been over six years since the 2019 PortSwigger research and more than two decades since the original Watchfire disclosure. Despite this long history, the threat has never been more prevalent. While incremental improvements, tightening RFC language and patching individual parsing flaws remains valuable, they preserve a reactive, cat-and-mouse dynamic in which new variations of the attack continually emerge.
The root cause is inherent to HTTP/1.1’s design, which tolerates a degree of ambiguity in message framing and parsing that makes uniform implementation exceptionally difficult. Every attack vector and CVE examined in this white paper traces back to the same underlying pattern, developers misinterpreting, selectively applying, or failing to fully implement RFC requirements as originally intended by the IETF.
In contrast, HTTP/2, eliminates the vulnerable text-based framing model of HTTP/1.1 in favour of a binary protocol where request boundaries are no longer of concern. This inherently closes off many of the parsing inconsistencies that enable request smuggling. If widely and correctly implemented from the user to the backend, HTTP/2 could address the fundamental design weaknesses responsible for this class of vulnerabilities. This migration is inevitable, and when it occurs it will fundamentally reshape request smuggling, turning a long-standing vulnerability into a largely obsolete attack vector.
References:
- https://github.com/unbit/uwsgi/issues/2560
- https://datatracker.ietf.org/doc/html/rfc2616#section-4.4
- https://www.cgisecurity.com/lib/HTTP-Request-Smuggling.pdf
- https://datatracker.ietf.org/doc/html/rfc7230
- https://github.com/portswigger/http-request-smuggler
- https://portswigger.net/research/http-desync-attacks-request-smuggling-reborn
- https://i.blackhat.com/USA-20/Wednesday/us-20-Klein-HTTP-Request-Smuggling-In-2020-New-Variants-New-Defenses-And-New-Challenges-wp.pdf
- https://bishopfox.com/blog/h2c-smuggling-request
- https://portswigger.net/research/http2
- https://portswigger.net/research/http1-must-die
- https://nvd.nist.gov/vuln/detail/CVE-2024-1135
- https://itinnovationstation.com/2025/02/04/understanding-ssrf-server-side-request-forgery/